

Les fournisseurs de LLM majeurs offrent une alternative à moitié prix pour les appels d’API : le batching.
Le principe est simple : vous acceptez d’obtenir la réponse à votre requête avec un délai supplémentaire, en échange d’une forte réduction sur le prix de l’appel.
Le batching est très utile si vous procédez régulièrement à des traitements par lots, avec des quantités de données importantes.
Le problème est que le batching est plus difficile à implémenter qu’un simple appel d’API LLM, car il faut gérer le délai d’attente au niveau du code.
Dans cet article, nous allons découvrir comment implémenter efficacement le batching sur Mistral en Python avec LangChain et LangGraph.
Créer un nouvel agent LangGraph
Tout d’abord, créons un nouvel agent en suivant la documentation officielle de LangGraph.
Python doit être installé sur votre ordinateur. Si vous ne connaissez pas encore Python, vous pourrez être intéressé par notre formation Python IA LLM Débutant en une journée.
# Python >= 3.11 is required.
pip install -U "langgraph-cli[inmem]"
git clone https://github.com/lbke/langgraph-demo-basic-agent-mistral --origin upstream batching
cd ./batching
pip install -e .Dans cet exemple, on utilise le template LangGraph Mistral de LBKE. Si vous souhaitez utiliser un autre fournisseur de LLM, vous pouvez utiliser le template de base de LangGraph via le CLI LangGraph.
# Si vous préférez utiliser un autre fournisseur que Mistral
langgraph new ./batching-autre-fournisseur --template new-langgraph-project-pythonEnfin, n’oubliez pas de configurer le fichier .env avec votre clé d’API. Les clés d’API Mistral peuvent être créées sur cette page.
cp .env.example .env
# Configurez MISTRAL_API_KEY dans ce fichier .envAprès cette étape, langgraph dev vous permet de faire tourner un agent.
Les étapes pour mettre en place le batching
Nous allons utiliser la Batch API de Mistral. La même approche fonctionne bien sûr aussi avec la Batch API d’OpenAI et le Batch Processing de Claude.
Les ingrédients pour mettre en place le batching dans LangGraph sont les suivants :
- Une variable d’état pour stocker l’identifiant unique du batch.
- Un noeud pour déclencher le batch.
- Une arête pour vérifier l’avancement des calculs du batch.
- Un noeud pour récupérer les résultats.
L’identifiant unique du batch est un peu comme un ticket de parking, on le conserve précieusement pour pouvoir retrouver votre batch. On mobilise pour cela l’état du graphe et la notion de mémoire court-terme avec les checkpointers.
Si perdez l’identifiant du batch, pas de panique : les batches sont généralement visibles dans l’interface administrateur de votre fournisseur LLM.
Il faut ensuite déclencher deux appels du graphe LangGraph : le premier pour déclencher le calcul avec vos inputs, et le second pour obtenir le résultat. Si les calculs ne sont pas terminés lors du second appel à votre agent LangGraph, alors il faudra recommencer plus tard.
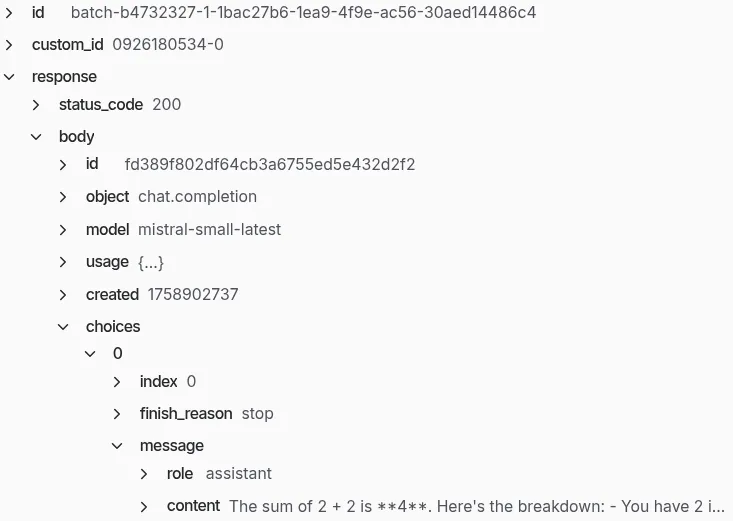
Vous obtenez enfin un résultat, ici la réponse à une question difficile : combien donne 2+2. Le message généré par le LLM est imbriqué dans une réponse complète qui vous fournit aussi les erreurs, les tokens utilisés etc. pour des usages avancés.
Implémentation du batching avec LangGraph et Mistral
Le CLI LangGraph gère tout l’aspect “checkpointing” pour nous et LangChain Studio fournit l’interface graphique. En termes de code, notre seule tâche est donc de créer un graphe LangGraph qui gère l’état du batch, comme ci-dessous.
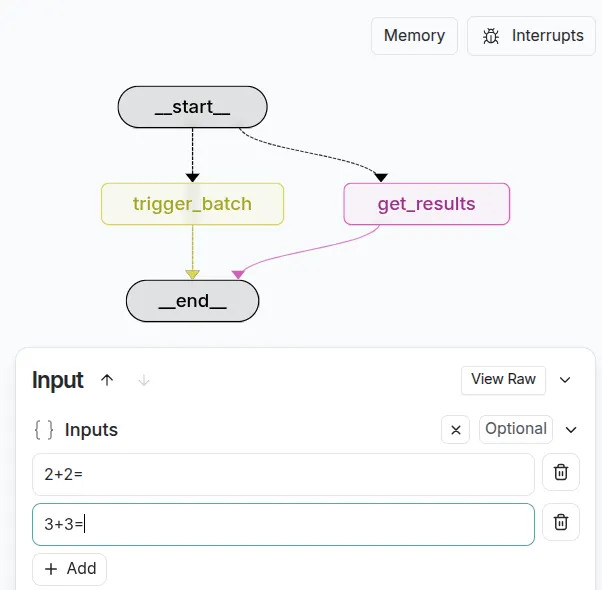
Le code est assez complexe, car l’API de batching nécessite plusieurs étapes pour être activée. Retrouvez le code complet de démonstration sur le dépôt GitHub lbke/langgraph-batching-api.
En bonus, vous pouvez retrouver une version alternative fonctionnant entièrement sur le cloud sans aucune installation, avec le batching d’Anthropic, Google Colab et Google Drive dans ce notebook.
Peut-on appeler une API LLM gratuitement ?
Utiliser les APIs de batching permet de réduire les coûts d’opération systèmes fondés sur les LLM. Cela est très utile, car beaucoup d’usages peuvent tolérer un délai de réponse pour économiser des frais : traiter des masses de documents, lancer des analyses hors des heures de travail… D’autant que la réponse reste assez rapide (en général) pour des requêtes simples.
Une réduction de 50% n’est peut-être pas encore suffisante pour vous. Vous cherchez une API totalement gratuite ? OpenRouter propose une liste de modèles accessibles gratuitement. Il sont en général limités dans l’usage mais suffisent pour apprendre. Le batching est plutôt à privilégier pour réduire les coûts dans un contexte professionnel, avec des modèles avancés et des API payantes sans limite d’usage.

