

Les embeddings, ou plongements vectoriels en français, aident à représenter efficacement des données complexes comme le texte, les images, l’audio ou la vidéo.
Ils sont conçus pour représenter la sémantique de la donnée d’origine. Par exemple, les embeddings des phrases “J’aime le nutella” et “crêperie près de chez vous” sont censés être proches.
Il s’agit concrètement de vecteurs denses de taille fixes, c’est-à-dire des tableaux de chiffres, qui sont construits par un modèle d’intelligence artificielle à partir des données d’entrée.
Voici par exemple deux phrases, et deux embeddings calculés pour ces phrases. Notez que les tableaux se ressemblent, car les deux sujets sont liés, même si aucun mot-clé n’est commun !
phrase_1="Bienvenue sur le blog de LBKE"
embedding_1=[0.12,0.01,-0.23]
phrase_2="Formation à l'IA agentique"
embedding_2=[0.11,0.03,-0.29]Nous avons déjà défini les embeddings dans notre lexique de l’IA générative. Cependant, il s’agit d’une notion complexe qui mérite son propre article : voici une définition détaillée de ce qu’est un embedding.
Des vecteurs sémantiques
Les embeddings représentent le texte ou les images avec un vecteur de taille fixe, mais surtout, ils capturent la signification sémantique des données : deux embeddings proches représentent des concepts proches.
Par exemple “la mer”, “l’océan” et “je vais me baigner à Saint-Tropez” auront des vecteurs très proches dans l’espace de plongement.
Les distances qui définissent si les embeddings sont proches ou éloignés sont simplement des calculs mathématiques. Il en existe plusieurs, et le choix idéal dépend du contexte. Les distances les plus courantes sont la distance euclidienne (tracer un trait entre les deux embeddings et mesurer sa longueur), la distance cosine (mesurer l’angle entre les embeddings), et le produit vectoriel (dot product) qui tient en même temps compte de la direction et de l’écart entre les embeddings.
Voici un autre exemple d’embeddings, en trois dimensions :
# 🐱 miaou
chat = [0.82, 0, -0.4]
# 🐶 Proche du chat mais différent
chien = [0.79, 0, -0.6]
# 🐢 Proche des animaux ET des ninjas
tortue ninja = [-0.22, 0.91, -0.7]
# ✈️ Très différent des animaux
avion = [0.25, -0.42, 0.97] En représentant les mots, les phrases ou les documents sous forme de vecteurs, l’IA peut effectuer des opérations comme la recherche sémantique, la classification et la recommandation de contenu sans s’appuyer sur une correspondance exacte des mots-clés.
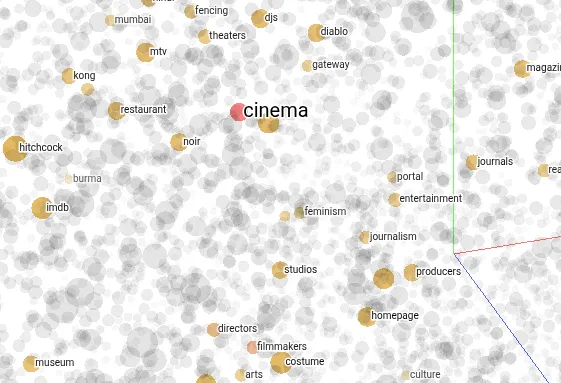
Vous pouvez visualisez un nuage d’embeddings projetés en 3D sur le site de tensorflow. On voit que le mot “cinéma” est proche de “costume”, “hitchcock” ou encore “audience”.
Vecteurs denses ou creux ?
Ces vecteurs denses contiennent parfois des centaines ou des milliers de dimensions, chaque combinaison de dimension contribuant à un aspect de la signification.
Mathématiquement, il s’agit de directions dans l’espace de plongement, l’espace qui contient tous les embeddings possibles pour une taille de vecteur donnée.
On parle de vecteurs denses car il existe aussi des vecteurs creux (“sparse” en anglais), avec de nombreux zéros.
Les vecteurs creux restent très utiles pour la recherche de mots-clés exacts, typiquement via l’algorithme BM25. Les valeurs à 0 représentent les mots absents d’un document, tandis que les valeurs non nulles représentent des fréquences d’apparition. Exemple dans la base Milvus.
Le problème est qu’il faut ainsi autant de dimensions dans le vecteur qu’il y a de mots dans le vocabulaire : là où un embedding dense peut comporter quelques centaines de valeurs et très bien représenter des documents complexes, un vecteur creux pourrait en compter des centaines de milliers pour gérer un vocabulaire étendu.
Pour aller plus loin, cet article d’IBM donne une très bonne introduction au principe des embeddings.
Comment sont générés les embeddings ?
Les embeddings proviennent de modèles d’apprentissage, ils sont donc créés par les IA.
Par exemple, les LLM représentent typiquement leurs entrées et sorties sous forme d’embeddings, et génèrent aussi des embeddings “internes” au fil de leurs calculs.
Tout comme notre cerveau transforme l’information en signaux électriques qui ne correspondent pas vraiment à une langue donnée, le LLM transforme ses entrées en embeddings et génère en sortie des embeddings qui seront finalement retraduits en tokens (~ en mots) pour constituer sa réponse.
 Un robot pensant en embeddings, généré par Mistral AI (via le modèle Flux de Black Forest)
Un robot pensant en embeddings, généré par Mistral AI (via le modèle Flux de Black Forest)
Il existait déjà des modèles d’embeddings avant l’IA générative, comme Word2Vec, mais les modèles d’embeddings modernes utilisent le plus souvent l’architecture Transformers, tout comme les LLM. Cela leur permet de traiter des séquences de longueur variable (embedding de phrases, de documents) et pour plusieurs typologies de données complexes (texte, images, audio).
Les LLM produisent naturellement des embeddings mais on utilise plutôt des modèles dédiés pour générer des embeddings de qualité, on parle alors d’apprentissage de représentation. OpenAI utilise par exemple l’algorithme open-source Matryoshka (“poupées russes”) pour créer des embeddings, et a récemment lancé des modèles d’embedding améliorés : text-embedding-3-small et text-embedding-3-large, qui offrent de meilleures performances et des prix plus bas par rapport aux versions précédentes. Il y a beaucoup de recherche dans ce domaine, par exemple Google présentait en 2024 Gecko, un algorithme d’embedding très efficace même avec un faible nombre de dimensions, ce qui accélère les calculs de distance. Le modèle open source Qwen3 est aussi de grande qualité.
Le modèle all-MiniLM-L6-v2 est utilisé par certains frameworks pour fournir des embeddings calculables directement sur une machine personnelle, via Onnx.
Recherche documentaire et similarité sémantique : un usage clé des embeddings
Les embeddings sont extrêmement utiles pour créer des moteurs de recherche sémantiques, qui comprennent vraiment le sens de nos recherches. Ou en tout cas font mieux qu’un moteur de recherche par mots-clés exacts.
En effet, les embeddings permettent de trouver des informations pertinentes sans passer par un système de mots-clés, qui ne gère pas les synonymes et nécessite de maintenir un index inversé dans la base de données.
Par exemple, la requête “adopter un chat” aura un vecteur d’embedding proche de “trouver un refuge pour animaux” malgré l’absence de mots en commun.
L’implémentation de cette approche implique la comparaison d’embeddings en utilisant la similarité cosinus et des algorithmes de plus proches voisins (k-NN).
Voici un exemple de code effectuant un tel calcul :
from openai import OpenAI
import numpy as np
client = OpenAI()
# Générer des embeddings pour deux textes sémantiquement similaires
request = client.embeddings.create(
model="text-embedding-3-small",
input="adopter un chat"
)
possible_response = client.embeddings.create(
model="text-embedding-3-small",
input="trouver un refuge pour animaux"
)
# Extraire les vecteurs d'embedding
embedding1 = request.data[0].embedding
embedding2 = possible_response.data[0].embedding
# Calculer la similarité cosinus (plus élevée = plus similaire)
# (équivalent à un produit vectoriel si les vecteurs sont normalisés)
similarity = np.dot(embedding1, embedding2) / (np.linalg.norm(embedding1) * np.linalg.norm(embedding2))
# Devrait être élevée malgré l'absence de mots communs
print(f"Similarité : {similarity}") Bases de données vectorielles : une infrastructure pour les embeddings
Pour gérer un grand volume d’embeddings, par exemple pour représenter tous les documents d’une entreprise, une infrastructure spécialisée devient rapidement nécessaire.
Les bases de données vectorielles sont optimisées pour ce type de données et permettent des recherches de similarité à grande échelle.
En effet, une implémentation naïve de l’algorithme de plus proches voisins ne suffirait pas. Il faudrait comparer chaque requête de l’utilisateur à tous les documents de la base, ce qui n’est pas viable (complexité linéaire).
Une base de données vectorielle implémente donc des algorithmes ANN (Approximate Nearest Neighbors) tels que HNSW, qui est très bien décrit par Pinecone ou encore l’algorithme ANN haute performance de Turbopuffer, une solution utilisée par l’assistant de code Cursor pour indexer du code informatique.
En plus de Pinecone, on peut citer comme bases vectorielles open source Chroma, Milvus, ou encore le plugin pgvector pour PostgreSQL.
Leur niveau de complexité varie, Chroma est typiquement une bonne solution pour créer une petite base d’embeddings directement dans un script Python ou JavaScript, avec des fonctionnalités simples : recherche d’embeddings, filtrage via les métadonnées.
AWS a souligné au sens large le rôle important des “vector stores” dans les applications d’IA génératives.
LLM + recherche sémantique = RAG sémantique
Que se passe-t-il lorsque l’on réunit un LLM et une recherche sémantique ? On obtient l’architecture RAG, “retrieval-augmented generation”.
En ajoutant les résultats d’une recherche sémantique à la requête de l’utilisateur, on fournit un contexte utile au LLM qui en retour génère des réponses beaucoup plus précises et avec moins d’hallucinations.
On note qu’en pratique, le RAG peut être implémenté avec n’importe quel mécanisme de recherche, donc pas forcément une recherche sémantique fondée sur les embeddings. Il s’agit simplement d’une approche très courante car facile à mettre en place et idéale lorsque les demandes des utilisateurs sont formulées en langage naturel sans forcément fonctionner par mots-clés.
Comment bien choisir son modèle d’embeddings : mettre en place des mesures de succès
Lorsqu’ils créent un moteur de recherche sémantique ou un RAG, les développeurs peuvent choisir entre des modèles d’embedding pré-entraînés ou personnalisés.
Les modèles pré-entraînés sont des modèles génériques, qui ne sont pas optimisés pour un problème en particulier mais fournissent des résultats plutôt satisfaisants quel que soit le type de texte. Il s’agit d’embeddings génériques, applicables à de nombreuses tâches mais non optimisés pour une tâche spécifique.
On peut donc vouloir mettre en place un “fine-tuning” ou choisir un modèle spécialisé si l’on doit traiter des données avec une structure particulière. Par exemple Codestral Embed de Mistral AI est comme son nom l’indique spécialisé dans l’embedding de code informatique.
Aussi la taille des embeddings a un impact sur les performances : des plongements plus grands sont plus précis, mais aussi plus coûteux à stocker et récupérer.
Avant de se lancer dans ces comparaisons, la première étape est néanmoins de définir des métriques de succès. Le plus souvent, il s’agit de trouver un compromis entre la qualité des réponses obtenues pour votre utilisation des embeddings, le temps de calcul, et le coût financier. Des plateformes comme langfuse et LangSmith sont plébiscitées par les data scientists.
Le guide d’évaluation des chaînes de RAG de Hub France IA est une référence incontournable pour le cas du RAG.
Profitez de la puissance de la représentation sémantique dans vos applications
Les embeddings permettent aux algorithmes de saisir des relations sémantiques et des similitudes que seule la compréhension humaine pouvait cerner jusqu’à récemment.
En transformant l’information en vecteurs sémantiques de taille fixe très simples à manipuler, les modèles d’embedding ouvrent la voie à de nombreux usages utiles pour introduire l’IA en entreprise : construire des moteurs de recherche précis, des chatbots fiables, ou encore trier des documents complexes.
Pour aller plus loin sur le plan technique, cet article récapitule très bien l’histoire des embeddings et leur fonctionnement.

