
Commençons par un truisme assumé : la veille est essentielle, et ce quelle que soit votre activité. Mais pour un organisme de formation certifié Qualiopi comme LBKE, cette évidence devient une exigence réglementaire. Il ne suffit pas de reconnaître l’importance de la veille : il faut la structurer, l’organiser, et surtout, en produire des preuves concrètes. La démarche doit être formalisée afin de répondre précisément aux trois indicateurs du Référentiel National Qualité : la veille légale et réglementaire (indicateur 23), la veille sur les évolutions des compétences, des métiers et des emplois (indicateur 24), ainsi que la veille sur les innovations pédagogiques et technologiques (indicateur 25).
Dans notre démarche d’automatisation de nos processus, nous nous sommes donc naturellement intéressés à celui de la veille.
Conseils pratiques
- Pour des raisons de sécurité : créez une adresse et un compte dédiés à la veille dans n8n
- N’hésitez pas à discuter avec la doc AI de n8n ; si la documentation de n8n se révèle souvent laconique et donc insuffisante, une discussion avec leur IA peut néanmoins vous aider à concevoir des workflows répondant à vos besoins spécifiques.
Pourquoi concevoir un workflow pour la collecte de données et un workflow pour l’analyse des données ?
Pour automatiser notre veille, nous allons construire deux workflows séparés : un premier (objet de cet article) qui se concentre sur la collecte des données, et un second qui analysera ces données pour produire nos fiches de veille. Le choix de diviser le processus en plusieurs workflows relève essentiellement de deux motivations :
- Mise en place d’un système anti-erreurs (méthode Poka-Yoke) : prendre l’habitude de séparer les workflows, et donc de fragmenter les processus, est un bon moyen d’éviter les erreurs critiques. Cela permet d’introduire des contrôles humains dans le workflow. Prenons un exemple : vous créez un workflow complet qui automatise la publication de posts Linkedin à partir des articles que vous publiez sur votre site. Une étape intermédiaire ne fonctionne plus et renvoie un message d’erreur : vous publiez alors sur Linkedin des posts avec les messages d’erreur, alors que fragmenter votre workflow en introduisant un contrôle humain entre les différents workflows permet d’éviter ce genre d’erreurs critiques.
- Praticité : si vous souhaitez construire plusieurs workflows d’analyse de données à partir des résultats obtenus grâce au workflow de collecte de données, cela est possible. Intégrer l’ensemble du processus dans un seul workflow bride vos capacités d’adaptation pour la suite.
Première approche : enregistrer au format texte les mails de veille reçus sur votre boîte mail dans un dossier sur Google Drive
Chez LBKE, nous avons une boîte mail dédiée à la veille. Bien sûr, en vue de la prochaine étape (analyse des données), vous pourrez également alimenter ce dossier avec des documents que vous déposerez manuellement dans ce dossier.
L’idée est de transformer les mails reçus sur l’adresse email dédiée en fichiers texte dans le dossier Google Drive. Pour cela :
-
On met en place un premier nœud Google Gmail « Get many messages » : on renseigne le credential précédemment créé (voir notre article sur l’authentification OAuth), on indique « Message » dans le champ « Resource ». Selon le volume que l’on souhaite récupérer, on coche « Return all » ou non ; si non, on précise la limite de messages que l’on souhaite télécharger. Afin d’obtenir le HTML du mail, et notamment le champ « textAsHtml », il faut décocher l’option « Simplify ». Nous vous conseillons, notamment dans le cadre d’une phase de test, de limiter le nombre de mails récupérés. En effet, dans l’hypothèse d’ajouts de nœuds IA dans la suite du workflow, il vaut mieux limiter le nombre d’appels d’API à ChatGPT par exemple, surtout dans le cadre d’une simple phase de test. On a alors 1 item en entrée, et 50 items en sortie.
-
On met en place un nœud Markdown qui va prendre, en entrée, le HTML du mail au format JSON et le transformer en fichier .txt. Le mode est ici « HTML to Markdown ». Dans le champ « HTML », il faut indiquer le champ « textAsHtml » issu du json, soit l’expression : « {{ $json.textAsHtml }} ». Vous pouvez nommer la clé de destination « markdown ».
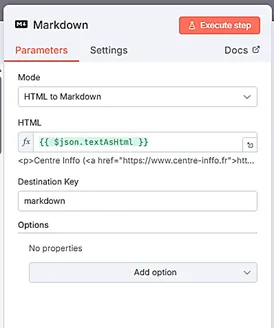
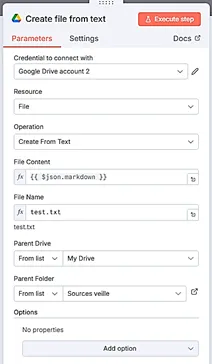
- On crée un nœud Google Drive « Create file from text », qui va permettre de créer, pour chaque fichier Markdown, un fichier texte. On indique le credential préalablement créé pour Google Drive. Dans le champ « File content », il faut renseigner le champ markdown : {{ $json.markdown }}. Dans File Name, renseignez le titre du mail (vous le trouverez dans les informations issues de l’étape précédente : {{ $json.subject }}. Dans le champ « Parent Drive », on indique le Drive dans lequel se situera le dossier. Dans le champ « Parent Folder », on indique le dossier dans lequel on souhaite stocker ses sources de veille, et donc ces emails transformés en fichiers texte.
Si vous consultez votre dossier contenant tous les fichiers source de veille, vous constaterez qu’on y trouve désormais les mails imprimés en fichiers texte.
Stocker ses mails au format texte est intéressant, toutefois en général, les informations exploitables figurent rarement dans le corps du mail, mais sont accessibles sur Internet en cliquant sur les liens disponibles dans le mail. On va donc s’intéresser à un second workflow, qui va récupérer les URLs présentes dans les mails et récupérer leur contenu au format HTML.
Deuxième approche : lister les liens présents dans les mails de veille, les filtrer, récupérer le contenu de ces liens sur Internet, et enregistrer ces documents dans votre dossier Google Drive
Tout d’abord, nous allons extraire les liens pertinents présents dans les mails des newsletters et les sauvegarder sous forme de tableau.
Une discussion avec l’IA de n8n nous a permis d’identifier les principales étapes de ce workflow :
-
Comme pour la première approche, on déclenche le workflow à l’aide d’un nœud Google Gmail « Get many messages ». On décoche « Simplify » afin d’obtenir en sortie le HTML du mail, et notamment le champ « textAsHtml ».
-
On extrait les liens du contenu à l’aide d’un nœud HTML, avec l’opération « Extract HTML Content ». Cet article publié sur le blog n8n présente un cas d’usage similaire, qu’il est utile de consulter.
- Dans le champ JSON Property, il faut indiquer le champ « textAsHtml » issu du nœud précédent. Il s’agit ensuite de préciser à n8n quelles valeurs nous souhaitons extraire :
- Dans le champ « Key », vous devez indiquer le nom des champs extraits tels qu’ils seront désignés ensuite. Nous pouvons les nommer « item » ; cela n’a pas tant d’importance.
- Nous souhaitons extraire le lien entre les guillemets dans les balises <a href=“…’’>. Ainsi, dans le champ « CSS Selector », il faut indiquer : a
- Dans le champ « Return Value » : Attribute
- Dans le champ « Attribute » : href Vous pouvez cocher « Return Array » si vous souhaitez obtenir le résultat sous forme de tableau.
-
On ajoute un nœud « Split out » : en sortie du nœud précédent, les URLs de chaque mail sont regroupées dans un tableau « item ». Il y a donc autant de tableaux « item » que de mails, et chaque tableau contient toutes les URLs figurant dans le mail. On souhaite plutôt obtenir plusieurs items individuels, pour pouvoir ensuite les filtrer et les traiter un par un. Dans « Fields to split out », indiquer : le nom du tableau, item ici, puis dans « Include » : no other fields, afin de ne conserver que les URLs. On a désormais autant d’items individuels qu’il y a d’URLs dans tous les mails que vous avez reçus. Transformer notre tableau d’URLs en items individuels est indispensable avant de pouvoir les filtrer.
-
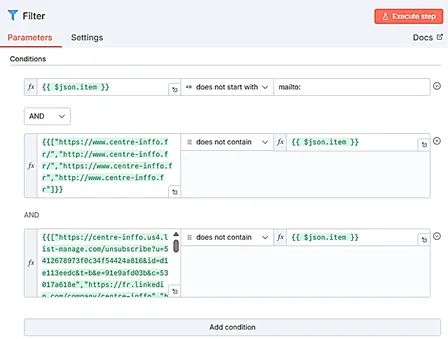
Nœud Filter : ce nœud est important car il va vous permettre de « nettoyer » l’ensemble des liens extraits à l’étape précédente, par exemple en retirant les URLs menant aux pages d’accueil, aux liens réseaux sociaux des entreprises/organismes qui vous ont envoyé le mail, ou encore les liens de désinscription. Il y a ainsi potentiellement beaucoup de liens que vous souhaiterez supprimer. Le nombre de conditions dans le nœud « Filter » étant limité (vous ne pouvez ajouter plus de 10 conditions), il s’agit alors d’indiquer dans un tableau, dans le premier champ d’une condition, la liste des liens que vous souhaitez voir supprimés. Vous sélectionnez ensuite la condition : Array => « does not contain ». Dans le second champ de la condition vous indiquez la désignation de chacune des URLs indépendantes, soit {{ $json.item }}. Vous pouvez par ailleurs explorer les différentes conditions existantes pour choisir la plus appropriée.
- Nœud Remove Duplicates : permet de supprimer les URLs doublons.
- Nœud Limit : nous ajoutons un nœud « Limit » afin de limiter le nombre de requêtes HTTP qui seront lancées. En effet, pour l’instant, lorsque nous lançons les requêtes HTTP sur plusieurs centaines d’URLs, le nœud HTTP Request sature et ne répond plus. Nous sommes en train de réfléchir à des solutions pour éviter ce petit problème, nous éditerons cet article lorsque nous aurons mis en place la solution ! Pour le moment donc, nous fixons le nombre maximum d’URLs à 10.
- Nœud Markdown : pour mettre en forme le HTML.
- Nœud Google Drive Create file from text : il faut indiquer {{ $json.data }} dans le champ « File content ».
Conclusion : pistes de finalisation et d’amélioration
Ce premier essai pose la colonne vertébrale d’un workflow de collecte des données de veille qui va devoir s’enrichir, avant d’envisager ensuite de s’atteler à l’automatisation du processus d’analyse des données de veille. En particulier, voici les pistes d’amélioration sur lesquelles nous allons travailler :
- Améliorer l’extraction des informations utiles dans la page HTML. Par exemple ce lien issu d’une newsletter de Centre Inffo mène vers une page donnant seulement un aperçu de l’article ; il faut une nouvelle requête pour récupérer l’article dans ce cas particulier.
- Gérer les nombreuses requêtes HTTP pour télécharger les articles sans saturer les sites. Il faut mettre en place un requêtage par lots (batching).
- Intégrer des nœuds d’IA pour prioriser directement les liens à explorer en profondeur, ou encore pour générer un nom de document clair et synthétique.
- A la suite de ce workflow : créer des workflows d’analyse de données.
N’hésitez pas à nous suivre sur Linkedin pour connaître la suite !

