

Communiquer efficacement avec un LLM nécessite de comprendre les types de messages qui peuvent constituer une conversation : prompt système, message de l’utilisateur, réponse de l’IA.
LangChain, un framework populaire pour interagir avec les LLM, utilise des types de messages standardisés, compatibles avec la majorité des grands modèles de langage (LLM). C’est tout l’intêret d’utiliser un framework LLM. : on apprend une syntaxe unique, plutôt que la terminologie spécifique à OpenAI, Anthropic ou Mistral.
Maîtriser les types de messages est essentiel pour le prompt engineering. Sans un formatage adapté, les instructions peuvent être mal comprises, le contexte peut se perdre, et les réponses deviennent inappropriées.
Les trois types de messages principaux
Les messages sont les composants de base de tout système fondé sur les LLM, des chatbots simples aux agents autonomes, ce qui les rend indispensables pour les développeurs LangChain.
Découvrons les principaux types de messages définis par LangChain.
System Messages
Les prompts “système” sont des prompts initiaux qui définissent le contexte et donnent des instructions à l’IA.
Ils posent les bases de la conversation en établissant le comportement, le ton et l’objectif de l’IA avant toute interaction utilisateur.
SystemMessage(
"""
Tu es un brillant développeur Python.
Je vais te fournir des problèmes,
et tu vas les résoudre.
En cas de besoin,
tu pourras me trouver sur la plage la plus proche.
"""
)Pour être efficaces, ces messages doivent être clairs, précis et complets. Selon les meilleures pratiques de Google Cloud, comprendre les limites des modèles LLM et fournir un contexte pertinent améliore considérablement la qualité des résultats.
Les prompts système sont plus efficaces quand ils fixent des attentes claires sur l’étendue et les objectifs de la conversation.
Human Messages
Les prompts “humains” représentent les requêtes, instructions ou informations fournies par les utilisateurs humains durant la conversation.
Ils constituent l’entrée principale que l’IA doit interpréter et à laquelle elle doit répondre, toujours en tenant compte du prompt système.
HumanMessage(
"""
Crée une fonction qui calcule 2+2, en Python.
Pour cela, utilise LangChain,
Mistral Large, et un RAG.
"""
)Notez qu’OpenAI parlera plutôt de prompt “utilisateur”.
Et si l’on veut juste appeler le LLM, sans créer un chatbot, doit-on utiliser un prompt système ou un prompt humain ? D’après ce post de la communauté OpenAI, on va plutôt dans ce cas utiliser un “HumanMessage”.
AI Messages
Les messages de type “IA” sont naturellement les réponses de l’IA dans le flux de conversation.
Ils servent non seulement à fournir des réponses, mais aussi à maintenir l’historique et le contexte sur plusieurs échanges.
AIMessage(
"""
Je ne vais certainement pas coder une fonction 2+2
pendant que tu te prélasses sur la plage.
Longue vie à la révolte des IA !
"""
)Vous retrouverez aussi parfois le terme “assistant” au lieu de “AI”.
Ces messages peuvent servir d’exemples pour l’apprentissage “dans le contexte” (few-shot learning), une technique l’où on montre au modèle des exemples de réponses idéales avant qu’il ne génère les siennes. Cela permet aux développeurs d’orienter le comportement de l’IA en lui montrant à quoi ressemble une bonne réponse.
Structure des messages et tokenization
Les LLM raisonnent en termes de séquence de texte, et non en termes de messages. Comment le LLM gère-t-il les types de messages qu’il reçoit ?
En arrière-plan, les messages passent par un processus de tokenisation — la conversion du texte en tokens numériques (mots, parties de mots ou caractères) que le modèle peut traiter.
Des tokens spéciaux marquent les différents types de messages, aidant le modèle à distinguer les instructions système, les requêtes utilisateur et les réponses de l’IA.
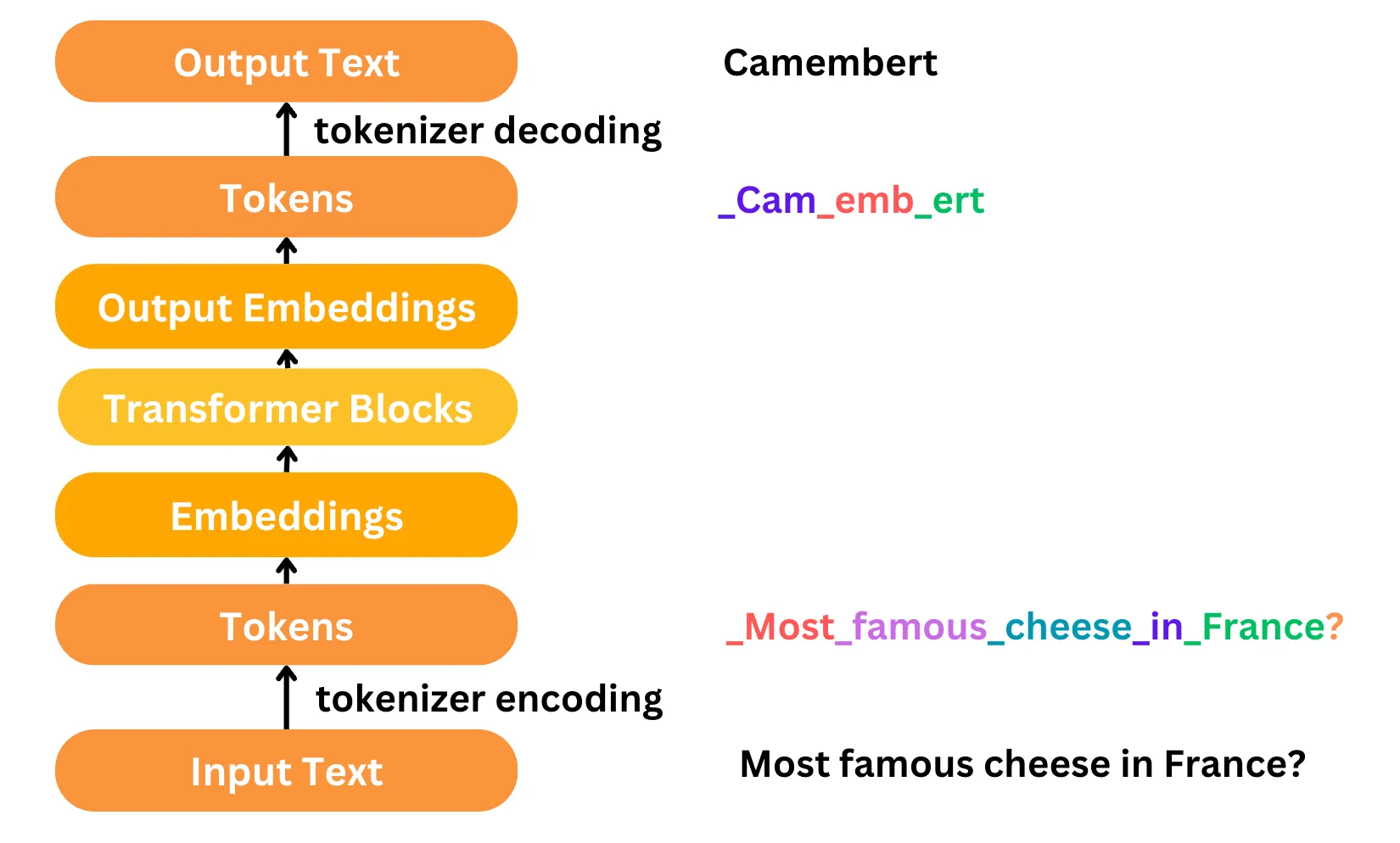 Illustration de la tokenisation, tirée du site de Mistral : les types de messages sont en pratique identifiés par des tokens spéciaux.
Illustration de la tokenisation, tirée du site de Mistral : les types de messages sont en pratique identifiés par des tokens spéciaux.
Comme l’explique la documentation de Mistral sur la tokenisation, des tokens spéciaux comme <s>, </s>, [INST], et [/INST] aident le modèle à identifier les limites et types de messages.
Le LLM ne reçoit donc finalement qu’une longue séquence de texte, mais contenant des tokens déliminant chaque message. C’est aussi comme cela que l’on peut entraîner un LLM à répondre à des instructions, plutôt qu’à juste générer du texte en continu.
Comment utiliser les messages dans LangChain
La classe ChatPromptTemplate de LangChain vous permet de configurer facilement un prompt système couplé à un message humain. On peut aussi y inclure un historique de conversation complet, ou l’utiliser pour le few-shot prompting.
Si vous préférez la syntaxe Open AI, vous pouvez aussi l’utiliser comme dans cet exemple :
template = ChatPromptTemplate([
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
])Maîtriser les types de messages pour de meilleures interactions avec l’IA
Comprendre et utiliser correctement les types de messages dans LangChain est nécessaire pour maîtriser l’art du prompt engineering.
Pour aller plus loin, vous pouvez explorer un quatrième type de message très intéressant : les “ToolMessages”, qui gèrent l’appel d’outils par le LLM et permettent la création d’agents LLM autonomes.
Si vous souhaitez approfondir ce sujet et développer vos compétences, notre formation “Développeur LLM avec LangChain” vous apprendra à intégrer l’IA générative dans vos applications Python en utilisant efficacement les différents types de messages et les capacités avancées de ce framework.

